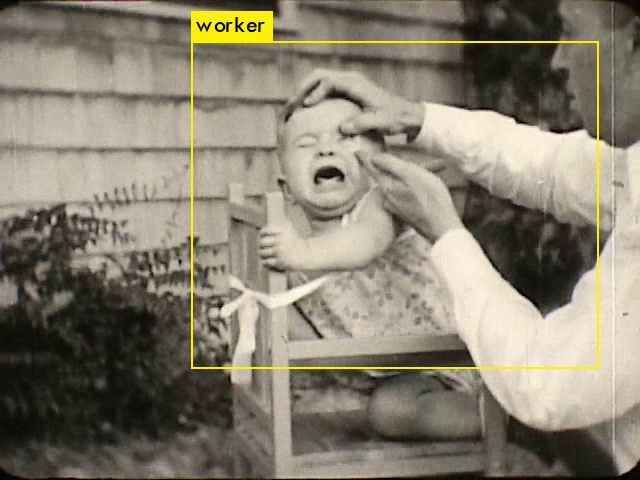
Què és el que veus YOLO9000?
YOLO9000 és una xarxa neuronal de reconeixement d’objectes entrenada amb un dataset de 9.418 paraules i milions d’imatges. Els experiments d'aquesta categoria estan enfocats a investigar-ne el funcionament: entendre què veu i com parla.




35mm_A-30Geografia-2335mm_A-31Geografia-2435mm_A-32Geografia-2535mm_A-33Geografia-2635mm_A-34Geografia-2735mm_A-35Geografia-2835mm_A-36Geografia-2935mm_A-37Geografia-3035mm_A-38Geografia-3135mm_A-39Geografia-3235mm_B-01Human_Chimp-0135mm_B-02Human_Chimp-0235mm_B-03Human_Chimp-0335mm_B-04Human_Chimp-0435mm_B-05Human_Chimp-0535mm_B-06Human_Chimp-0635mm_B-07Human_Chimp-0735mm_B-08Human_Chimp-0835mm_B-09Human_Chimp-0935mm_B-10Human_Chimp-1035mm_B-11Human_Chimp-1135mm_B-12Human_Chimp-1235mm_B-13Human_Chimp-1335mm_B-14Human_Chimp-1435mm_B-15Human_Chimp-1535mm_B-16Human_Chimp-1635mm_B-17Human_Chimp-17A_trip-01Human_Chimp-18A_trip-02Human_Chimp-19A_trip-03Human_Chimp-20A_trip-04Miscelania-01Aeri-01Miscelania-02Aeri-02Miscelania-03Aeri-03Miscelania-04Aeri-04Miscelania-05Aeri-05Miscelania-06Aeri-06Miscelania-07Berkeley-01Miscelania-08Berkeley-02Miscelania-09Berkeley-03Unfortunate01Berkeley-04Unfortunate02Creator-01Unfortunate03Creator-02Unfortunate04Creator-03Unfortunate05Creator-04Unfortunate06Creator-05Creator-06Creator-07Creator-08Foc-01Foc-02Foc-03Foc-04Foc-05Foc-06Foc-07Foc-0835mm_A-01Foc-0935mm_A-02Foc-1035mm_A-03Foc-1135mm_A-04Foc-1235mm_A-05Foc-1335mm_A-06Foc-1435mm_A-07Foc-1535mm_A-08Geografia-0135mm_A-09Geografia-0235mm_A-10Geografia-0335mm_A-11Geografia-0435mm_A-12Geografia-0535mm_A-13Geografia-0635mm_A-14Geografia-0735mm_A-15Geografia-0835mm_A-16Geografia-0935mm_A-17Geografia-1035mm_A-18Geografia-1135mm_A-19Geografia-1235mm_A-20Geografia-1335mm_A-21Geografia-1435mm_A-22Geografia-1535mm_A-23Geografia-1635mm_A-24Geografia-1735mm_A-25Geografia-1835mm_A-26Geografia-1935mm_A-27Geografia-2035mm_A-28Geografia-2135mm_A-29Geografia-22

cafephil-yolo9000-t10judge-c-yolo9000-t20Kandinsky_-_Bleu_de_ciel-yolo9000-t10‘Night Watch’, Rembrandt van Rijn, 1642358464-yolo9000-t10Ambassador Cornelis Calkoen at his Audience with Sultan Ahmed III, Jean Baptiste Vanmour, c. 1727 - c. 1730Christ Crowned with Thorns, Gerard van Honthorst, c. 1622Hieronymus_Bosch_-_Death_and_the_Miser_-_Google_Art_Project-yolo9000-t20Pieter_Bruegel_the_Elder_-_Peasant_Wedding_-_Google_Art_Project-yolo9000-t20Pieter_Bruegel_the_Elder_-_The_Parable_of_the_Blind_Leading_the_Blind_-_WGA3511-yolo9000-t20The Love Letter, Johannes Vermeer, c. 1669The Marriage at Cana, Jan Cornelisz Vermeyen, c. 1530 - c. 1532The Seven Works of Mercy, Master of Alkmaar, 1504_2The Seven Works of Mercy, Master of Alkmaar, 1504Thetriumphofdeath-yolo9000-t20_1



Taxonomies
En la visió artificial, l’elecció de les paraules per descriure la imatge és la tasca menys automàtica: se n’encarreguen els humans. Sobre la base d’aquests glossaris, la màquina actua com el nostre millor alumne: aprèn el que nosaltres li fem veure. Aconseguir que una visió artificial funcioni implica educar-la en un sistema particular de veure. Els experiments que segueixen es basen en la substitució del vocabulari de YOLO9000 per altres llistes de paraules.




Experts compulsius
Experiments en els quals s'han entrenat xarxes neuronal de visió artificial. Les categories d'entrenament provenen del món de l'art (estils artístics, col·leccions de museus o artistes) o de conceptes relatius a la producció de les imatges (eines o conceptes de composició).




'Winter_Scene'_oil_on_panel_painting_by_Hendrick_Avercamp,_c._1620,_Museu_de_Évora,_Portugal1687px-Mona_Lisa,_by_Leonardo_da_Vinci,_from_C2RMF_retouched757px-Anamorph_with_column01906-watercolor-painting-of-landscape-of-harvard-university-boston-massachusetts25988080263_081c0b6e67_b38111166521_0e6f85f6ab_b26889200531_2982f88b0d_bcorso-interior-design-arezzoDeer_at_night_(10696965166)jerusalem-1221599_960_720maxresdefault-1Mount_Kilimanjaro_NasaWorldWindnypl.digitalcollections.510d47dd-e7fb-a3d9-e040-e00a18064a99.001.wnypl.digitalcollections.a66286fc-e859-0953-e040-e00a180655af.001.qoffice-1966380_960_720Orwell_video_game_screenshot_7

Generatiu
Experiments realitzats amb Pix2Pix; una xarxa GAN (generative adversarial network), és a dir, pensada per a la generació d’imatges. Aquesta eina s’ha ideat principalment per transformar l'estil d'una imatge i funciona a partir d'un entrenament amb parelles d'imatges –la xarxa aprendria a fer automàticament el pas d’un tipus d'imatge de la parella a l'altra. En els nostres experiments hem intentat produir una imaginació maquínica –la xarxa neuronal després de l’entrenament– i jugar a estimular-la per provocar resultats inesperats.



Primers experiments
Experiments inicials amb eines de visió artificial centrades en la descripció de les imatges i l'anàlisi facial.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}