¿Qué es lo que ves, YOLO9000?
YOLO9000 es una red neuronal de reconocimiento de objetos entrenada con un dataset de 9.418 palabras y millones de imágenes. Los experimentos que siguen están enfocados a investigar su funcionamiento: entender qué ve y cómo habla.


Geografia-2235mm_A-30Geografia-2335mm_A-31Geografia-2435mm_A-32Geografia-2535mm_A-33Geografia-2635mm_A-34Geografia-2735mm_A-35Geografia-2835mm_A-36Geografia-2935mm_A-37Geografia-3035mm_A-38Geografia-3135mm_A-39Geografia-3235mm_B-01Human_Chimp-0135mm_B-02Human_Chimp-0235mm_B-03Human_Chimp-0335mm_B-04Human_Chimp-0435mm_B-05Human_Chimp-0535mm_B-06Human_Chimp-0635mm_B-07Human_Chimp-0735mm_B-08Human_Chimp-0835mm_B-09Human_Chimp-0935mm_B-10Human_Chimp-1035mm_B-11Human_Chimp-1135mm_B-12Human_Chimp-1235mm_B-13Human_Chimp-1335mm_B-14Human_Chimp-1435mm_B-15Human_Chimp-1535mm_B-16Human_Chimp-1635mm_B-17Human_Chimp-17A_trip-01Human_Chimp-18A_trip-02Human_Chimp-19A_trip-03Human_Chimp-20A_trip-04Miscelania-01Aeri-01Miscelania-02Aeri-02Miscelania-03Aeri-03Miscelania-04Aeri-04Miscelania-05Aeri-05Miscelania-06Aeri-06Miscelania-07Berkeley-01Miscelania-08Berkeley-02Miscelania-09Berkeley-03Unfortunate01Berkeley-04Unfortunate02Creator-01Unfortunate03Creator-02Unfortunate04Creator-03Unfortunate05Creator-04Unfortunate06Creator-05Creator-06Creator-07Creator-08Foc-01Foc-02Foc-03Foc-04Foc-05Foc-06Foc-07Foc-0835mm_A-01Foc-0935mm_A-02Foc-1035mm_A-03Foc-1135mm_A-04Foc-1235mm_A-05Foc-1335mm_A-06Foc-1435mm_A-07Foc-1535mm_A-08Geografia-0135mm_A-09Geografia-0235mm_A-10Geografia-0335mm_A-11Geografia-0435mm_A-12Geografia-0535mm_A-13Geografia-0635mm_A-14Geografia-0735mm_A-15Geografia-0835mm_A-16Geografia-0935mm_A-17Geografia-1035mm_A-18Geografia-1135mm_A-19Geografia-1235mm_A-20Geografia-1335mm_A-21Geografia-1435mm_A-22Geografia-1535mm_A-23Geografia-1635mm_A-24Geografia-1735mm_A-25Geografia-1835mm_A-26Geografia-1935mm_A-27Geografia-2035mm_A-28Geografia-2135mm_A-29



cafephil-yolo9000-t10judge-c-yolo9000-t20Kandinsky_-_Bleu_de_ciel-yolo9000-t10‘Night Watch’, Rembrandt van Rijn, 1642972a5b4a1c9738a7f23aead797e3035b-yolo9000-t10358464-yolo9000-t10Ambassador Cornelis Calkoen at his Audience with Sultan Ahmed III, Jean Baptiste Vanmour, c. 1727 - c. 1730Christ Crowned with Thorns, Gerard van Honthorst, c. 1622Hieronymus_Bosch_-_Death_and_the_Miser_-_Google_Art_Project-yolo9000-t20maxresdefault-yolo9000-t10Pieter_Bruegel_the_Elder_-_Peasant_Wedding_-_Google_Art_Project-yolo9000-t20Pieter_Bruegel_the_Elder_-_The_Numbering_at_Bethlehem_-_Google_Art_Project-yolo9000-t20_1Pieter_Bruegel_the_Elder_-_The_Numbering_at_Bethlehem_-_Google_Art_Project-yolo9000-t20_2Pieter_Bruegel_the_Elder_-_The_Numbering_at_Bethlehem_-_Google_Art_Project-yolo9000-t20_3Pieter_Bruegel_the_Elder_-_The_Numbering_at_Bethlehem_-_Google_Art_Project-yolo9000-t20_4Pieter_Bruegel_the_Elder_-_The_Numbering_at_Bethlehem_-_Google_Art_Project-yolo9000-t20Pieter_Bruegel_the_Elder_-_The_Parable_of_the_Blind_Leading_the_Blind_-_WGA3511-yolo9000-t20Pieter_Bruegel_the_Elder_-_The_Sermon_of_Saint_John_the_Baptist_-_Google_Art_Project-yolo9000-t20_1Pieter_Bruegel_the_Elder_-_The_Sermon_of_Saint_John_the_Baptist_-_Google_Art_Project-yolo9000-t20Pieter_Brueghel_the_Elder_-_The_Dutch_Proverbs_-_Google_Art_Project-yolo9000-t20_1Pieter_Brueghel_the_Elder_-_The_Dutch_Proverbs_-_Google_Art_Project-yolo9000-t20_2Pieter_Brueghel_the_Elder_-_The_Dutch_Proverbs_-_Google_Art_Project-yolo9000-t20The Love Letter, Johannes Vermeer, c. 1669The Marriage at Cana, Jan Cornelisz Vermeyen, c. 1530 - c. 1532The Seven Works of Mercy, Master of Alkmaar, 1504_2The Seven Works of Mercy, Master of Alkmaar, 1504The_Garden_of_Earthly_Delights_by_Bosch_High_Resolution-yolo9000-t20_1The_Garden_of_Earthly_Delights_by_Bosch_High_Resolution-yolo9000-t20_2The_Garden_of_Earthly_Delights_by_Bosch_High_Resolution-yolo9000-t20_3The_Garden_of_Earthly_Delights_by_Bosch_High_Resolution-yolo9000-t20_4Thetriumphofdeath-yolo9000-t20_1



Taxonomías
En la visión artificial, la elección de las palabras para describir la imagen es la tarea menos automática: corre a cargo de los humanos. En base a estos glosarios, la máquina actúa como nuestro mejor alumno: aprende lo que nosotros le hagamos ver. Conseguir que una visión artificial funcione implica educarla en un sistema particular de ver. Los siguientes experimentos se basan en la sustitución del vocabulario de YOLO9000 por otros listados de palabras.




Expertos compulsivos
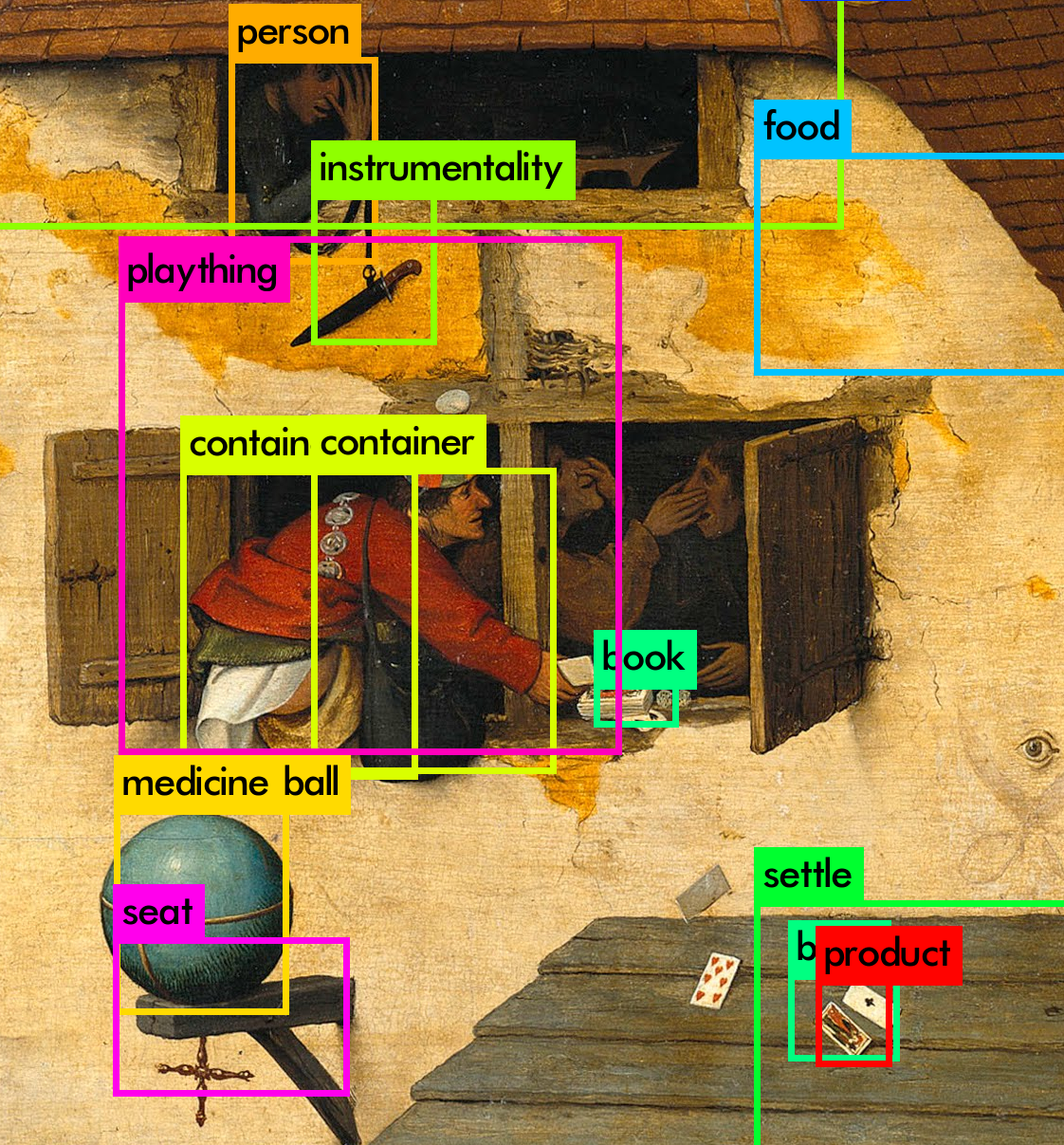
Experimentos en los que se han entrenado redes neuronal de visión artificial. Las categorías de entrenamiento provienen del mundo del arte (estilos artísticos, colecciones de museos o artistas) o de conceptos relativos a la producción de las imágenes (herramientas o conceptos de composición).


'Winter_Scene'_oil_on_panel_painting_by_Hendrick_Avercamp,_c._1620,_Museu_de_Évora,_Portugal1687px-Mona_Lisa,_by_Leonardo_da_Vinci,_from_C2RMF_retouched757px-Anamorph_with_column01906-watercolor-painting-of-landscape-of-harvard-university-boston-massachusetts25988080263_081c0b6e67_b38111166521_0e6f85f6ab_b26889200531_2982f88b0d_bcorso-interior-design-arezzoDeer_at_night_(10696965166)jerusalem-1221599_960_720maxresdefault-1Mount_Kilimanjaro_NasaWorldWindnypl.digitalcollections.510d47dd-e7fb-a3d9-e040-e00a18064a99.001.wnypl.digitalcollections.a66286fc-e859-0953-e040-e00a180655af.001.qoffice-1966380_960_720Orwell_video_game_screenshot_7



Generativo
Experimentos realizados con Pix2Pix; una red GAN (generative adversarial network), esto es, pensada para la generación de imágenes. Como se ha explicado antes, esta herramienta se ha ideado principalmente para transformar el estilo de una imagen, y funciona a partir de un entrenamiento con pares de imágenes –la red aprendería a hacer automáticamente el paso de un tipo de imagen del par al otro–. En nuestros experimentos hemos intentado producir una imaginación maquínica –la red neuronal después del entrenamiento– y jugar a estimularla para provocar resultados inesperados.



Primeros experimentos
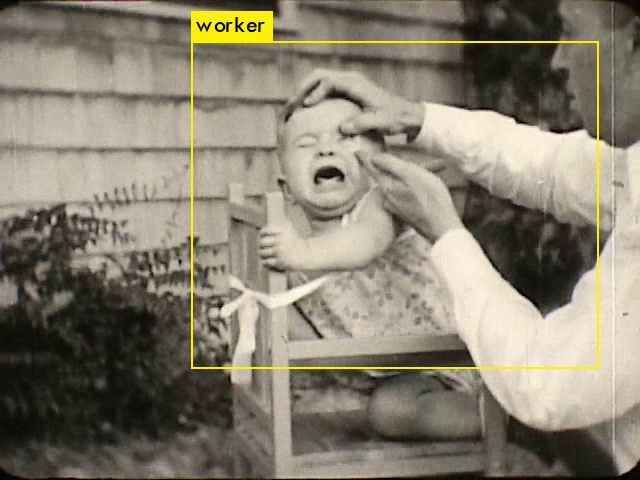
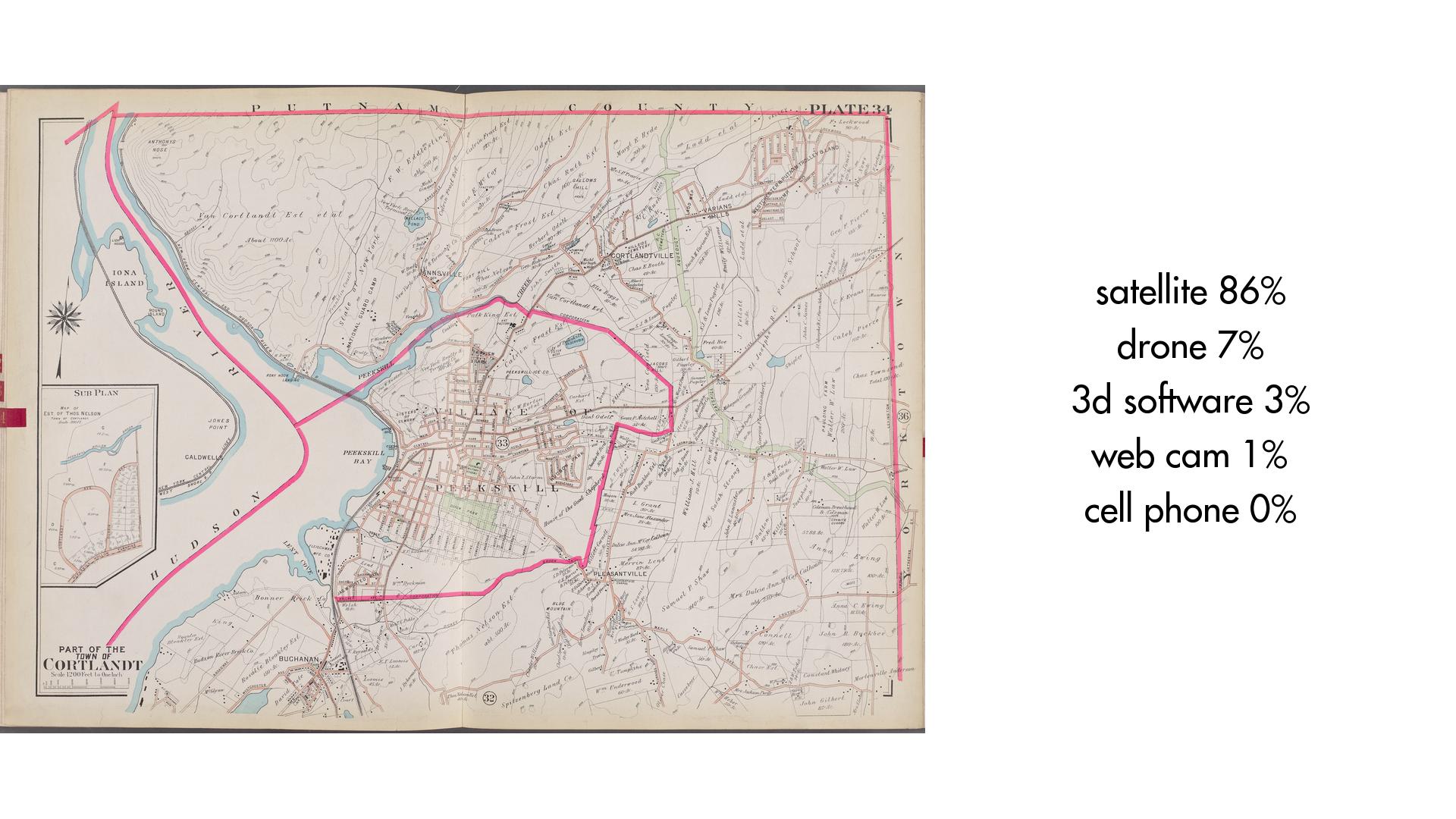
Experimentos iniciales con herramientas de visión artificial centradas en la descripción de las imágenes y el análisis facial.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}